This is Bookbag running a store
Actual screenshots, actual conversations. The widget your customers see, and the dashboard your team lives in.
Watch it handle a customer, start to finish
A shopper opens chat, asks about returns, then asks for a gift idea. The agent answers from the store’s own policies and catalog — instantly, in the brand’s voice — and recommends a $48 product while it’s at it. This recording is a real conversation with a Bookbag agent.
- Answers from your policies, not generic AI guesses
- Recommends products from your own catalog
- Matches your brand color and tone
- Hands off to your team the moment it should
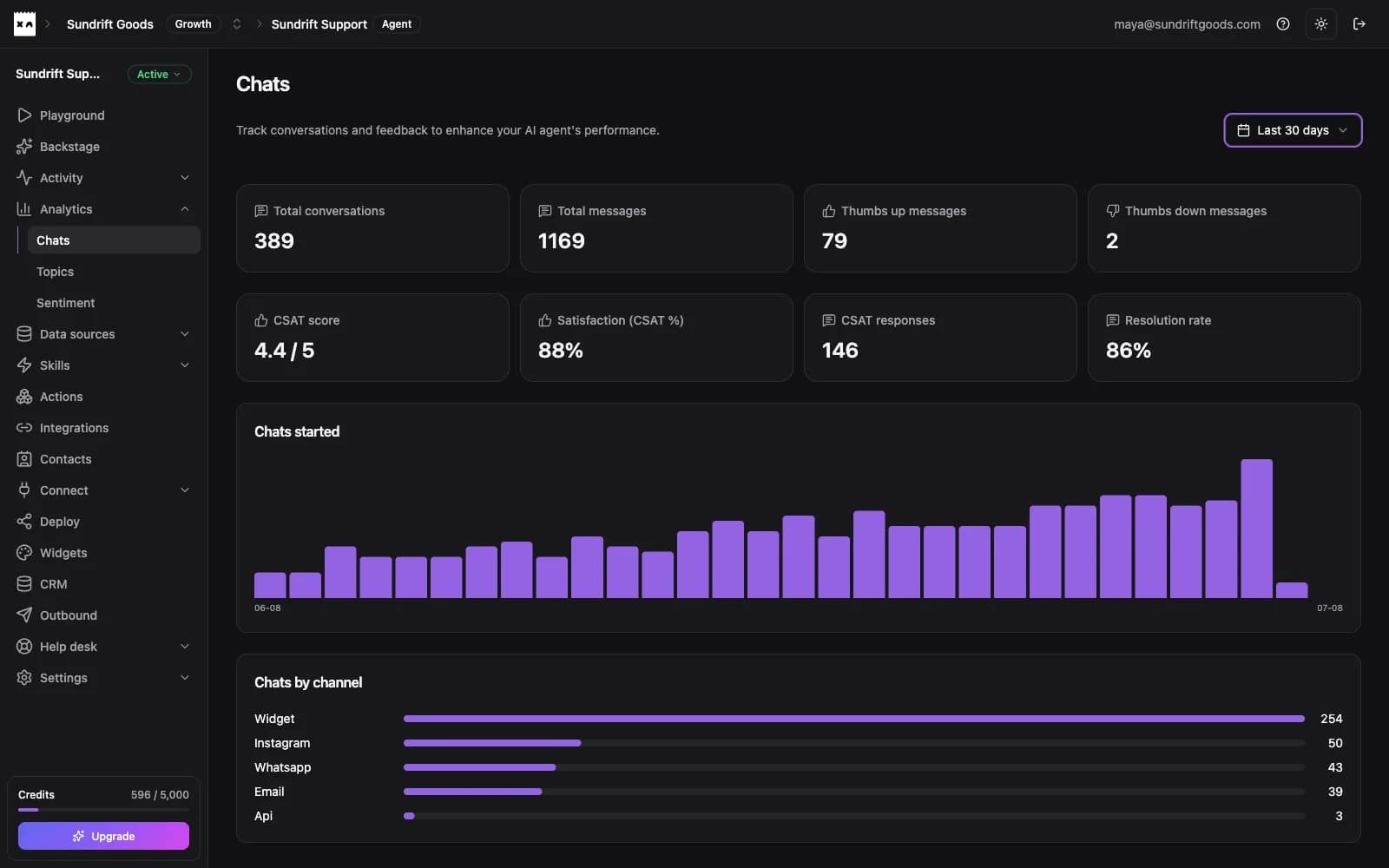
Conversations, CSAT, resolution rate, and channel breakdown for the last 30 days. Support stops being a black box.
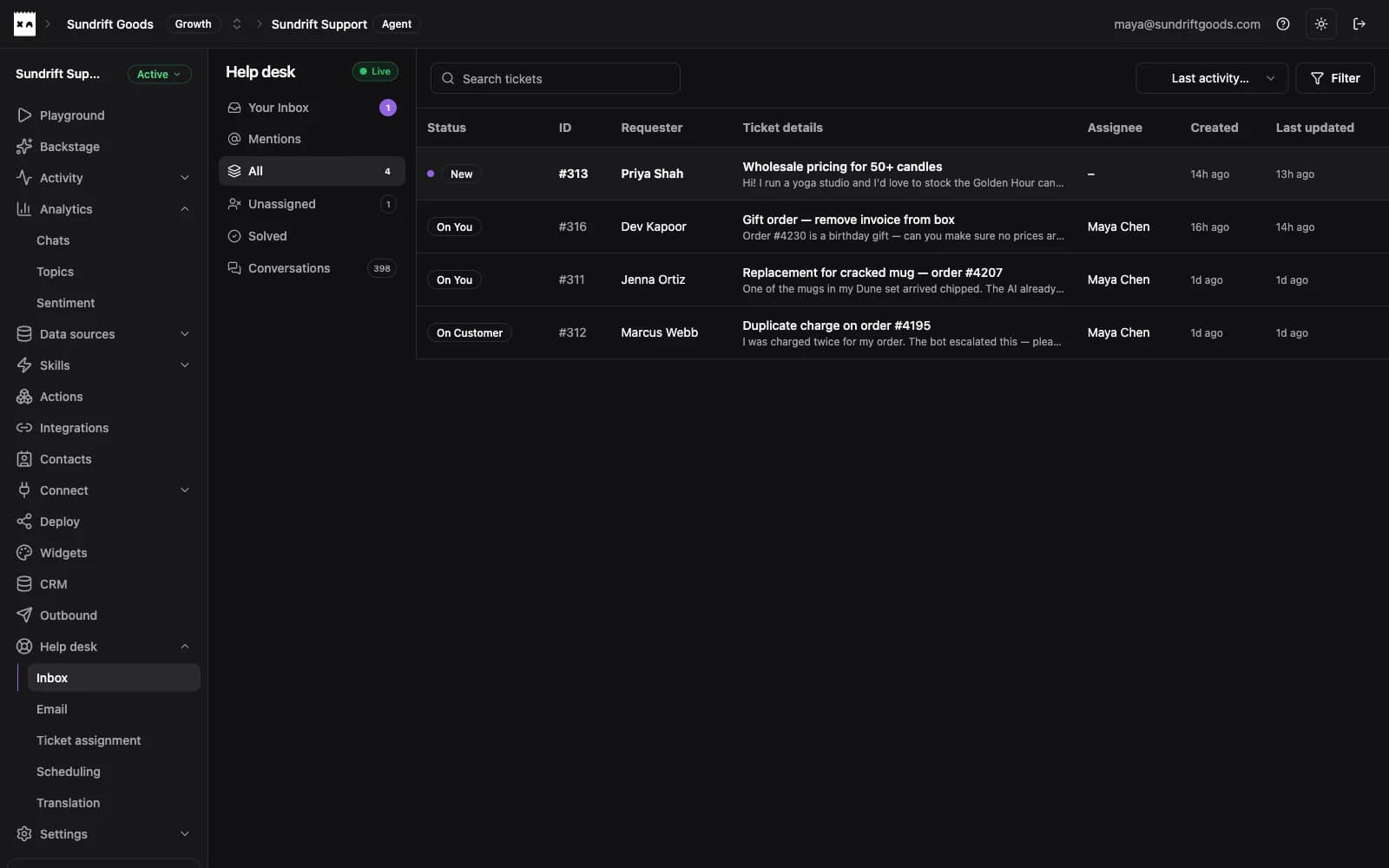
Widget, email, Instagram, WhatsApp — tickets land in one help desk with statuses, assignment, and AI summaries.
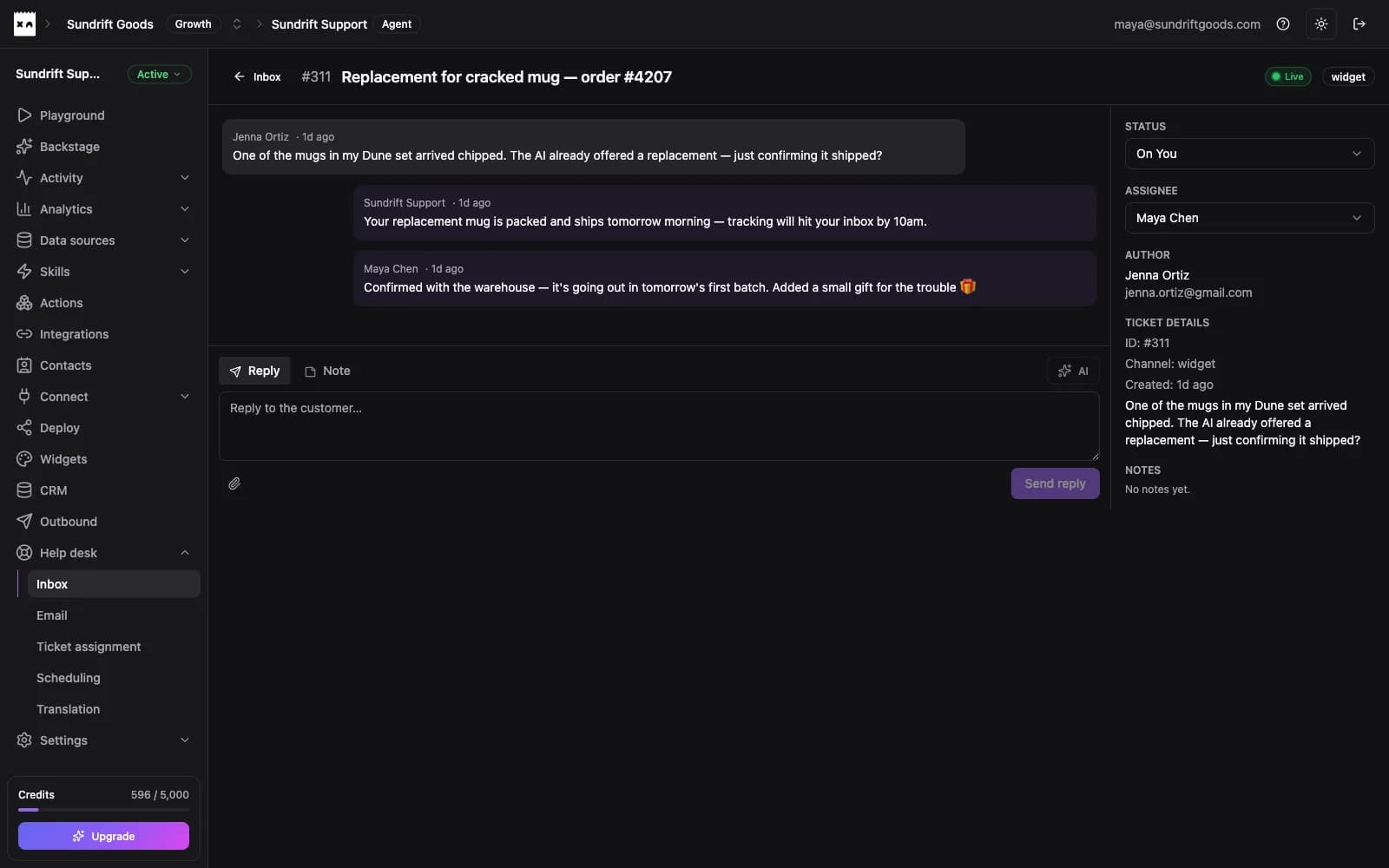
The AI offers the replacement; your teammate confirms the details. Handoffs keep the full thread and context.
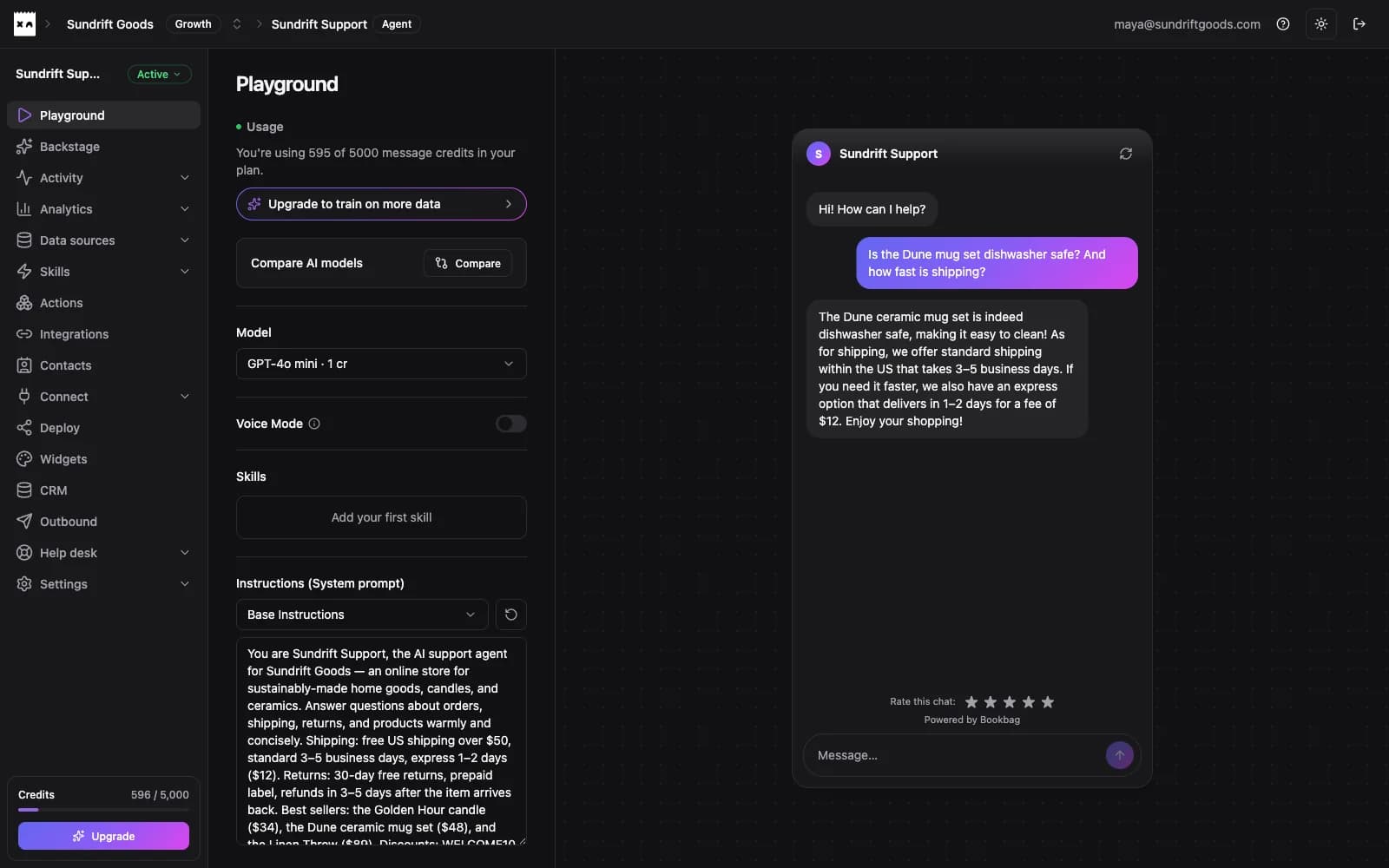
Pick the model, set the instructions, and test live in the playground before anything reaches a customer.
Switch without the surprises
The most common 1-star reviews of metered chat tools are about billing shocks, bots that hallucinate, and widgets that slow your store. We built the opposite — by design.

You set the spending limit
Choose a monthly message cap and we never raise it for you. No auto-upgrades, no mid-month “you’ve been bumped to a higher plan.”
It never just goes dark
Hit your cap and the agent keeps capturing leads or hands off to your team — so a busy month never means a blank chat and a lost sale.
You’re not billed for spam
Bot floods and abusive bursts are rate-limited automatically and never count against your quota. Your messages are for real customers.
It won’t make things up
When the answer isn’t in your knowledge, the agent says so or hands off — instead of confidently inventing an answer that costs you a sale.
You see what to fix
A Knowledge Gaps report shows every unsure answer grouped by topic, so quality never silently degrades the way it does on set-and-forget bots.
It won’t slow your store
The widget loads lazily and never blocks your page — no PageSpeed hit, no sticky-cart overlap. Your Core Web Vitals stay intact.
Founders are switching — fast.
The reviews speak for themselves. You’ll want in.
“The “where’s my order” flood used to eat our mornings. Now it’s handled before we’re even online.”

“I switched on a Tuesday and by the weekend it had recovered $4,200 in carts and was upselling better than my team did. Support literally pays for itself now — I tell every founder I know.”

“It actually starts the return and pulls live tracking — our old chatbot just linked the policy page.”

“Flat pricing means peak season doesn’t blow up our bill. Live in a day, zero dev work.”

“Cut our WISMO tickets in half overnight.”
“Customers think it’s a human. It’s that good.”
“Recovered $4k in carts the first week.”
“Returns basically handle themselves now.”
“Our CSAT jumped from 4.1 to 4.8.”
“Set up before my coffee got cold. ☕”
“Peak season. Zero panic. First time ever.”
“Replaced Gorgias and saved ~60%.”
“It upsells better than my team did.”
“24/7 support without hiring anyone.”
“Cut our WISMO tickets in half overnight.”
“Customers think it’s a human. It’s that good.”
“Recovered $4k in carts the first week.”
“Returns basically handle themselves now.”
“Our CSAT jumped from 4.1 to 4.8.”
“Set up before my coffee got cold. ☕”
“Peak season. Zero panic. First time ever.”
“Replaced Gorgias and saved ~60%.”
“It upsells better than my team did.”
“24/7 support without hiring anyone.”
Deeper control — without the markup
Bring your own model, tune exactly how the agent thinks, and pay the provider directly. No per-message tax.
Your models, or ours. Bring your own key and keep your margin.
Run on Bookbag's models out of the box — or connect your own OpenAI or Anthropic key whenever you want. With your own key you pay the provider at cost on a predictable platform fee, with no per-message markup when traffic spikes. Most support tools don't even give you the choice.
- Pay providers directly — no per-message markup
- Flat platform price, even on your busiest day
- Switch GPT ↔ Claude per agent, anytime
Illustrative — flat platform fee + your provider’s at-cost usage vs. typical per-message pricing.
Design the conversation, not the code
Drag and connect action blocks to greet, qualify, capture leads, and hand off to a human — running right inside your agent’s chat.
Build a chatbot flow in minutes — no developers required.
Snap together action blocks on a canvas. Your bot handles the first level of every conversation and only loops in a human when it actually matters — so your team answers fewer repeats and never misses a lead.
- Send messages, buttons & quick replies
- Collect input and capture leads with a form
- Answer from your knowledge base with an AI block
- Branch on what the customer picks
- Hand off to a live agent at the right moment
Simple, predictable pricing
One price per reply, a spend cap you control, no per-resolution or per-seat fees. Free to start, no credit card.
Questions, answered
How is this different from a regular chatbot?+
Most chatbots only answer questions. Bookbag is an agent: it connects natively to Shopify and takes real actions — tracking orders, processing returns and refunds, recommending products, and recovering carts — then hands off to your team only when it should.
Does it work with Shopify?+
Yes — natively (plus WooCommerce and BigCommerce). Install it and the agent reads live order data and takes order actions with no custom development.
How much does it cost?+
Flat plans with no per-resolution fees. Free to start (no credit card), then $30, $110, or $350/mo as you grow.
How long does setup take?+
Most stores are live in under a day. Connect your store, set your tone, and add a one-line snippet.